The model is not the bottleneck. The harness is — and the agent can evolve it.
Strong models often already have the capability. What matters is whether the harness makes it show up — and whether, with the right loop, agents can improve that harness over time.
TL;DR
- Strong models often already have the capability. The harness decides whether it shows up: on TerminalBench 2.0, adding
self-verificationskill along with self-evolved harness achieves 76.5% pass rate. - Agents can learn their own harnesses — but only with the right loop. Agents could revise bad skills inside a single run, but more feedback was not better feedback, and human-curated skills still won when the loop never exposed the missing knowledge.
We ran A-EVOLVE on four agent benchmarks (SkillBench, MCP-Atlas, TerminalBench 2.0, SWE-Bench Verified) expecting to learn how agents improve. Instead, we kept seeing the same pattern: the model was often not the bottleneck. The harness was.
On long-horizon tasks, the gap between "the model can do this" and "the agent actually does it" often came down to the harness around it. Small harness changes could unlock an existing capability — or suppress it entirely.
A second surprise was that the harness itself did not have to stay fixed. A self-evolving agent could sometimes improve its own harness: add a bad skill, observe the drop, remove it, and carry the lesson into the next cycle. But that only worked when the loop made the right lesson legible.
Rule 1: The capability exists. The harness decides whether it shows up.
Most people explain agent failures as missing capability. Our runs kept pointing somewhere else.
On long-horizon tasks, frontier models often already know how to do the right thing. What fails is not the capability itself. What fails is whether the harness gets that capability to appear at the right moment.
Verification was the clearest example.
| Setting | What changed | Result |
|---|---|---|
| TerminalBench 2.0 | Add self-verification skill along with self-evolved harness |
76.5% pass rate |
| MCP-Atlas | Let the evolver write skills from scratch | 3 of 5 evolved skills centered on verification |
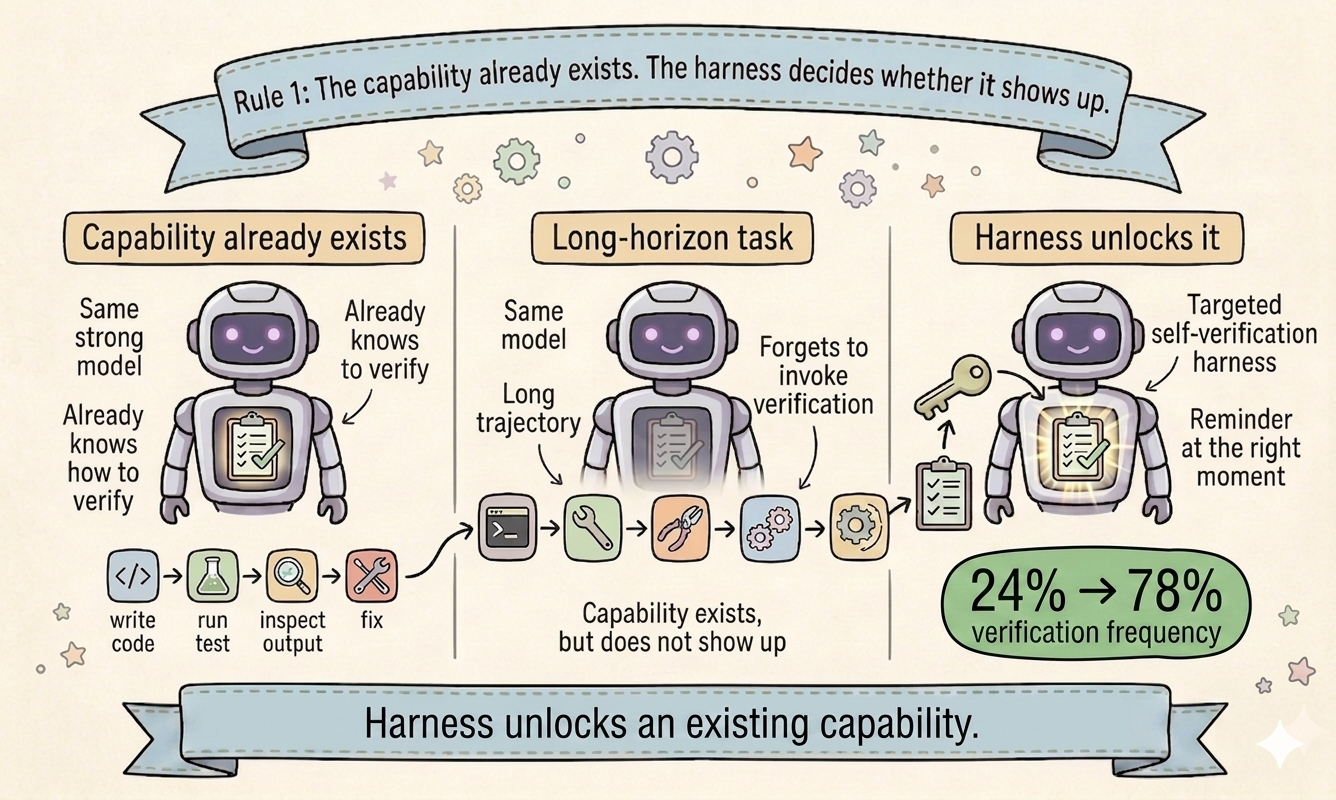
Opus 4.6 knows how to verify. It forgets on long-horizon tasks.
Opus 4.6 self-verifies all the time on short tasks. You can watch it in an interactive session: write code, run a test, inspect the output, fix what broke.
But on long-horizon TerminalBench 2.0 tasks, the same model often burns its budget executing commands and exits without checking anything.
The capability is there.
The deployment is not.
Our intervention was tiny: A self-verification skill plus a one-line system prompt nudge to lazy-load the skill at the end of the trajectory.
We did not teach Opus 4.6 how to verify.
We reminded it to do something it already knows how to do.
That single change delivered +33.33 percentage points on the 21 unstable tasks (33.33% → 66.67%). On the full benchmark, it achieves 76.5% pass rate.
More importantly, we find the nudged self-verification skill increaese the verification frequency from 24% to 78% on the full benchmark.
This is where the story got more interesting.
So the lesson is not just that harnesses matter.
It is that the harness is itself a design object.
A good harness unlocks capability (e.g., self-verification in the long-horizon task).
No one told the evolver to verify. Three of its five skills do.
We started with zero skills in the workspace: no entity-verification, no search-iteration, no anything. Just the base agent and 500 multi-step reasoning tasks.
Over 17 evolution cycles the evolver wrote 5 skills from scratch.
Three of the five carry verification as a core component.
We did not tell the evolver that verification matters. It arrived there on its own, because the tasks kept failing without it.
The recurring failure pattern was simple: the agent picked the wrong entity, failed to check it, and then built the rest of the trajectory on top of that error.
The model already knew how to compare names and attributes.
What it lacked was a harness rule that made that check happen.
So the evolver wrote one: after search, stop and verify the name match, attribute match, and content match. If anything is off, abort and retry.
After that, wrong_entity_complete fell from 4 to 2, and chained_reasoning_failure fell from 27 to 24.
The pattern showed up twice, in two very different settings:
- a human wrote a verification skill on TerminalBench, and performance rose
- an evolver rediscovered verification on MCP-Atlas, and the failure pattern shrank
The model did not need a new capability.
It needed a harness that made an existing capability show up.
Rule 2: Agents can learn their own harnesses — but only with the right loop.
Can agents learn their own harnesses? Yes. In a single automated run, we watched the evolver add a bad skill, get worse, remove it, and write down the lesson — twice.
But "autonomously" has real limits, and we found two.
The evolver corrected its own mistakes. Twice.
On MCP-Atlas, we started with an empty skill library and ran 17 evolution cycles over 500 tasks.
At cycle 12, the evolver added a skill called completeness-check. The next cycle dropped by about 10 percentage points. At cycle 13, it removed the skill and wrote the lesson into its own memory file:
"completeness-check skill added at C12 was associated with a −10% drop, removed at C13. Avoid adding generic checklist-style skills."
At cycle 15, it tried again with single-fact-lookup. Another ~10-point drop. At cycle 16, it removed that too.
Two full add → observe → remove → generalize cycles, with zero human intervention.
That is the important part. The system did not just accumulate harness content. It revised it. The harness became something the agent could learn from — and unlearn.
This did not happen by accident. Three design choices in the evolver loop made it possible:
- Delete permission. The evolver can remove skills, not just add or refine them. Without this,
completeness-checkstays in the workspace forever. - Labeled attribution. After each cycle the harness labels what changed and whether the score went up or down, and feeds that label back into the evolver's next prompt. The evolver sees "Cycle 12: added completeness-check, −3.4%" as a pre-computed line. It does not have to figure out causality from raw scores.
- Automated loop. No human approves or rejects proposed changes. The add-observe-remove cycle closes inside a single run, fast enough for the evolver to learn from its own mistakes before context shifts.
The evolver learned because the loop made cause and effect visible. That same dependency is also its ceiling.
More feedback made the evolver worse.
MCP-Atlas suggested that the evolver needed a feedback loop with the right amount of structure. To see how fragile that sweet spot was, we ran a controlled ablation on SWE-Bench Verified, varying how much detail the evolver saw after each failed attempt.
| Feedback level | Pass rate (13 hard tasks) |
|---|---|
| E01 — trajectory only, no score | 4/13 (30.8%) |
| E02 — score + failure type + edited files | 8/13 (61.5%) |
| E03 — + failing test names | 4/13 (30.8%) |
| E04 — + patch diffs | 2/13 (15.4%) |
Too little feedback hurt, as expected. The surprise was on the other side: full patch diffs were much worse than the mid-detail setting.
Why does more detail hurt? Full patch diffs anchor the evolver to the failed implementation. Instead of extracting a reusable pattern, it starts repairing the last patch, producing narrow fixes that overfit a single attempt. But the opposite extreme is also bad: with too little signal, the evolver cannot localize what went wrong well enough to propose a useful change. E02 works because it preserves the failure signal while abstracting away the failed implementation.
More feedback is not better feedback. The evolver needs the right level of detail, not all of it.
Human-curated skills still outperformed the evolver. The loop never exposed the missing constraint.
The harder limit was not self-correction. It was access to knowledge the loop never exposed.
On SkillBench's manufacturing-fjsp-optimization, a human-curated skill solved what the evolved skill could not. The difference was a single line the evolver never wrote:
"To achieve this, never start any operation earlier than the baseline."
That line is not in the task description. In this case, it reflects verifier-specific knowledge: a hidden constraint about how correctness is judged, recoverable only from testing, inspecting the verifier, or prior experience.
More broadly, this points to a larger limit of autonomous skill evolution. The evolver writes skills from scores and failure traces, but some important harness content depends on knowledge that never appears in those signals at all — including verifier logic, environment-specific constraints, or domain knowledge external to the trajectory.
That is why human-curated skills still sometimes outperform evolved ones. The gap is not better wording or stronger reasoning. It is access to information the loop never exposed.
This also suggests a concrete direction for future work. What the human contributed here was not intuition; it was a process for uncovering hidden constraints. Autonomous evolution currently lacks access to that process. But a process can be added to a loop — through verifier inspection, targeted probing, or richer interaction with the environment.